
Feb 12 2018
Significant but Irrelevant – Study on Correcting False Information
 A study from a few months ago is making the rounds due to recent write ups in the media, including Scientific American. The SA titles reads: “Cognitive Ability and Vulnerability to Fake News: Researchers identify a major risk factor for pernicious effects of misinformation.”
A study from a few months ago is making the rounds due to recent write ups in the media, including Scientific American. The SA titles reads: “Cognitive Ability and Vulnerability to Fake News: Researchers identify a major risk factor for pernicious effects of misinformation.”
The study itself is: ‘Fake news’: Incorrect, but hard to correct. The role of cognitive ability on the impact of false information on social impressions. In the paper the authors conclude:
“The current study shows that the influence of incorrect information cannot simply be undone by pointing out that this information was incorrect, and that the nature of its lingering influence is dependent on an individual’s level of cognitive ability.”
So it is understandable that reporters took that away as the bottom line. In fact, in an interview for another news report on the finding one of the authors is quoted:
“Our study suggests that, for individuals with lower levels of cognitive ability, the influence of fake news cannot simply be undone by pointing out that this news was fake,” De keersmaecker said. “This finding leads to the question, can the impact of fake news can be undone at all, and what would be the best strategy?”
The problem is, I don’t think this is what the study is saying at all. I think this is a great example of confusing statistically significant with clinically significant. It is another manifestation of over-reliance on p-values, and insufficient weight given to effect size.
Here’s the study – the researchers gave subjects a description of a woman. In the control group they asked them to rate her probable qualities, how much they liked her, how trustworthy she was, etc. In the intervention group they also gave the subject false information about her, that she sold drugs and shoplifted in order to support her shopping habit. They also gave a cognitive ability test to all subjects, and divided them into high cognitive ability (one standard deviation above average) and low cognitive ability) one standard deviation below average).
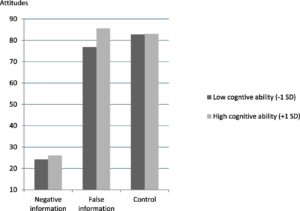
Above is the graph of the results (high definition version here). As you can see, in the control group both high and low cognitive subjects rated the fictitious person as an 82/100 in quality. The intervention group, after give the false negative information, rated her much lower, a 24/26 in the low/high cognitive ability groups respectively. Then, the false negative information was corrected – the subjects were told, never mind, this false information is not true. Now how would you rate the person? The high cognitive ability group then rated her as an 85, while the low cognitive ability group rated her as a 78. The difference between the 85 and the 78 was statistically significant.
I look at this data and what I see is that in both cognitive ability groups, the false information had about the same negative effect, and the correction had about the same corrective effect, and in fact essentially completely erased the effect of the false information. I am not impressed by a tiny but statistically significant effect.
The small effect size has two major implications. The first is that it calls into question the reality of the effect at all. Essentially, the study has a small signal to noise ratio, and this is problematic, especially when dealing with human subjects. It’s just too easy to miss confounding factors, or to inadvertently p-hack your way to a significant result. That probably has something to do with the replication problem in psychological research.
But even if you think the study is rock-solid (and I don’t), and the results are entirely reliable, the effect size is still really small. I don’t know how you can look at this data and conclude that the bottom line message is that people with lower cognitive ability (as defined in this study in a very limited way, but that’s another issue) had difficulty correcting false information. They corrected from a rating of 24 up to 78, with a control group rating of 82. Are you really making a big deal out of the difference between 78 and 82? Is that even detectable in the real world? What does it mean if you think someone’s personal qualities rank 78/100 vs 82/100?
With any kind of subjective evaluation like this, how much of a difference is detectable or meaningful is a very important consideration. I would bet that a difference between 78 and 82 has absolutely no practical implication at all. That means that effectively, even the people in the lower cognitive group, for all practical purposes, corrected the effect of the false information.
I am also not impressed by the difference between the low and high cognitive groups – 78 to 85. That is still not a difference with any likely practical difference. Even this small effect size may be an artifact of the fact that the high cognitive group over-corrected (compared to controls) by a small amount (also insignificant).
And yet the Scientific American headline writer wrote that with this research, “Researchers identify a major risk factor for pernicious effects of misinformation.” “Major” risk factor? I don’t think so. Minor and dubious is more like it. What this research does show is that subjects easily and almost completely corrected for misinformation when pointed out to them.
But even that conclusion is questionable from this data, because the research conditions were so artificial, and the researchers characterize them as ideal. The false information was quickly and unequivocally reversed. This is not always the case in the real world.
Unfortunately I see this phenomenon a lot. Social psychology studies take a tiny but statistically significant outcome, and then over-interpret the results as if it is a large and important factor. Then journalists report the tiny effect as if it is the bottom line result, leaving the public with a false impression, often the opposite of what the study actually shows.
We see this in medicine all the time also. This is the frequentist fallacy – if you can get that p-value down to 0.05, then the effect is both real and important. However, often times a statistically significant result is clinically insignificant. Further, small effect sizes are much more likely to be spurious – an illusion of noisy data or less than pristinely rigorous research methods.
This is why some journals are shifting their emphasis from p-values to other measures of outcome, like effect sizes. You have to look at the data thoroughly, not just the statistical significance.
Further, researchers have to be careful not to oversell their results, and science journalists need to put research results into a proper context.





{kind=link}