
Feb 06 2020
The Genetics of Cancer
 More than a thousand scientists working for over a decade in 37 countries have just published the results of their comprehensive analysis of cancer genetics – Pan-cancer analysis of whole genomes. This was a massive effort, facilitated by modern computing allowing for international collaboration. It is a good example of the collaborative nature of science. There are some interesting take-aways from the results, but first let’s review the basics of cancer.
More than a thousand scientists working for over a decade in 37 countries have just published the results of their comprehensive analysis of cancer genetics – Pan-cancer analysis of whole genomes. This was a massive effort, facilitated by modern computing allowing for international collaboration. It is a good example of the collaborative nature of science. There are some interesting take-aways from the results, but first let’s review the basics of cancer.
In healthy tissue there are multiple mechanisms to keep cells from reproducing and growing without limit. Cell proliferation is a carefully regulated process, and when that process goes awry one potential result is cancer. It has already been established for many cancers that they are caused by a combination of genetic mutations, which disable one or more of these regulatory mechanisms. The result are cells that will grow without limit, either in the blood or forming a solid tumor. Cancers can vary in terms of how aggressive they are – how fast do they grow, how much do they invade neighboring tissue, and how likely are they to metastasize (spread to remote areas).
Treating cancer involves removing tumors, and using drugs and radiation to kill rapidly dividing cells. Cancer cells are rapidly dividing, but so are some healthy tissues and this leads to significant side effects. Newer treatments block the formation of new blood cells to feed tumors, and also harness the immune system to attack cancer cells. Despite the fact that cancer is a horrifically complex set of diseases (not one disease), progress in our understanding and treatment of cancer has lead to a steady increase in survival.
The death rate from cancer in the US declined by 29% from 1991 to 2017, including a 2.2% drop from 2016 to 2017, the largest single-year drop ever recorded, according to annual statistics reporting from the American Cancer Society.
It is unlikely that there will ever be a “cure for cancer” but progress will lead to a steady slow improvement in survival, so that fewer and fewer people will actually die from their cancer, as opposed to living long enough to die from something else.
The new study promises to keep this steady progress going, by dramatically improving our understanding of the genetics of cancer. This is a basic science study, which means it does not deal directly with treatment, but the hope is that the knowledge gained can be translated into improvements in clinical treatment. This one study may fuel improvements in cancer treatments for decades.
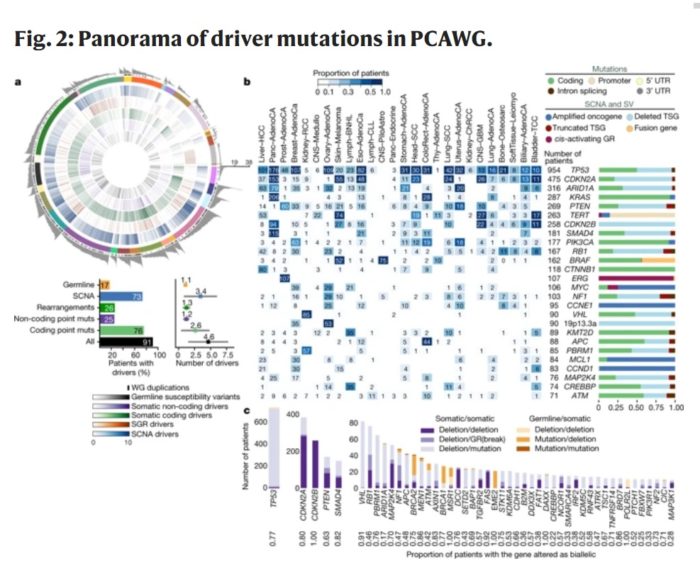
What the scientists did is whole genome analysis of 2,658 cancer, with matched healthy tissue (from the same patients) in 38 different cancer types. Up until now most cancer genetics has focused on genes – so-called coding regions that are directly translated into proteins. This study looks at the whole genome, coding and non-coding regions, for a more complete picture. Non-coding regions do contain a lot of “junk DNA” but also contain critical regulatory DNA. Also, mutations in non-coding regions may stiff have effects.
One key finding is that, on average, cancers have 4-5 driver mutations – mutations that cause physiological changes that result in the cells being cancerous. These mutations can occur in thousands of different combinations to cause cancer – reinforcing the diversity and complexity of this category of disease. However, in 5% of cases they found no driver mutations. This means there is still more to learn about the causes of cancer. The authors also think this was a limitation of the analysis itself – finding currently unknown mutations and linking them to the cancer.
The research was also able to date when mutations occurred. They used a technique similar to dating when mutations occurred in evolution. Cells in the body have the same kind of ancestral relationship as individuals or even species do:
One transition point is between clonal and subclonal mutations: clonal mutations occurred before, and subclonal mutations after, the emergence of the most-recent common ancestor. In regions with copy-number gains, molecular time can be further divided according to whether mutations preceded the copy-number gain (and were themselves duplicated) or occurred after the gain (and therefore present on only one chromosomal copy).
The more widespread a mutation is in a population of cancer cells, the earlier that mutation appeared. They found that some mutations may arise even decades before a cancer appears. This can happen because often one or two mutations do not cause cancer, but they can sit there for years or decades until more mutations happen in those cells that then result in cancer.
But the authors also found that sometimes a group of mutations can happen all at once, in single “catastrophic” events:
Three such processes have previously been described: (1) chromoplexy, in which repair of co-occurring double-stranded DNA breaks—typically on different chromosomes—results in shuffled chains of rearrangements; (2) kataegis, a focal hypermutation process that leads to locally clustered nucleotide substitutions, biased towards a single DNA strand; and (3) chromothripsis, in which tens to hundreds of DNA breaks occur simultaneously, clustered on one or a few chromosomes, with near-random stitching together of the resulting fragments.
There are more technical details, but those are the main findings. This study is partly the fulfillment of the promise of the human genome project, which was formally completed in 2003. The technology have advanced considerably since then, allowing for this kind of study in which several thousand whole genomes were sequenced. I suspect the promise of this study, in turn, will take additional decades to unfold, such is the nature of scientific research into such complex problems. It is studies like these that fuel the continued slow and steady progress in cancer survival, that will hopefully continue for more decades to come.




