
Mar 22 2019
Get Rid of “Statistical Significance”
A new paper published in Nature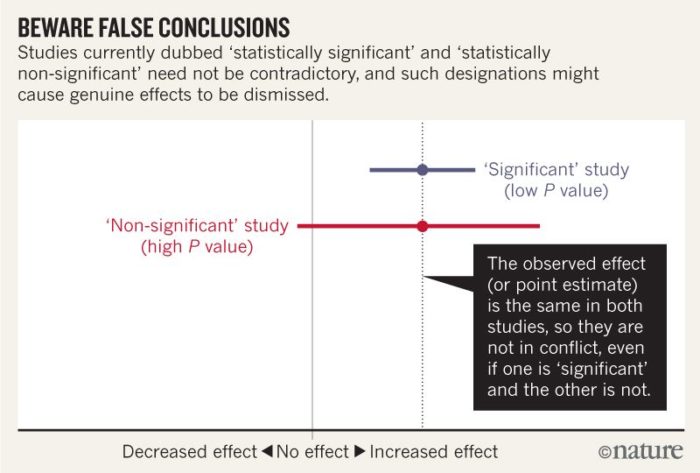 , and signed by over 800 researchers, adds to the growing backlash against overreliance on P-values and statistical significance. This one makes a compelling argument for getting rid of the concept of “statistical significance” altogether. I completely agree.
, and signed by over 800 researchers, adds to the growing backlash against overreliance on P-values and statistical significance. This one makes a compelling argument for getting rid of the concept of “statistical significance” altogether. I completely agree.
Statistical significance is now the primary way in which scientific results are recorded and reported. The primary problem is that it is a false dichotomy, and further it reduces a more thorough analysis of the results to a single number and encourages interpreting the results as all or nothing – either demonstrating an effect is real or not real.
The primary method for determining significance is the P-value – a measure of the probability that the results obtained would deviate as much as they do or more from a null result if the null hypothesis were true. This is not the same as the probability that the hypothesis is false, but it is often treated that way. Also, studies often assign a cutoff for “significance” (usually a p-value of 0.05) and if the p-value is equal to or less than the cutoff the results are significant, if not then the study is negative.
When you think about it, this makes no sense. Further, the p-value was never intended to be used this way. It is only the human penchant for simplicity that has elevated this one number to the ultimate arbiter of how to interpret the results of a study.
The consequences of this simplistic analysis is that the interpretation of study results are often misleading. The authors, for example, looked at 791 articles in 5 journals and found that half of them made wrong conclusions about the results based on overinterpreting the implication of “significance”.
Another consequence, which I have discussed previously, is p-hacking. This is the practice of tweaking the choices a researcher makes in terms of how to gather and analyze data in order to push the results over the magic line of significance. Many researcher admit to behavior that amounts to p-hacking. Further, when published results are analyzed they tend to suspiciously cluster around the cutoff for statistical significance.
Researchers and especially statisticians are increasingly recognizing that using the p-value as one number to determine statistical significance, and therefore whether or not the results of a study were “positive” or “negative,” is a monster that needs to be slayed. Several fixes have been proposed.
One paper suggests that the cutoff for significance be changed from 0.05 to 0.005 (in biomedical research). The point of this is to rebalance false-positives and false-negatives. They have a point, and from a practical point of view this is not a bad idea in some contexts, but it will not deal with the deeper problem of having a magical cutoff.
Some journals have simply banned p-values. That would certainly fix the problem of overrelying on p-values, but may be too draconian and unnecessary. The authors of the current article explicitly say that do not recommend banning p-value – just relying only on a arbitrary cutoff of p-value for significance.
There are also calls to shift more to other forms of statistical analysis, such as a Bayesian analysis, which takes into consideration the pre-test probability.
While experts disagree on the solution, they all seem to agree on the problem. Using an arbitrary cutoff of the p-value as the one measure of “significance” must go.
I like the general approach suggested in the current paper, which is to do a compatibility analysis. This is essentially what I do in an informal way – to look at all of the data analysis and ask, what kind of world are these data most compatible with?
So – we need to look at the prior probability, the quality of the data (methods, etc.), the effect size, the statistical magnitude of the effect, the sample size and applicability, any sources of bias or error, and the reproducibility of the results. We can then make a holistic analysis of all these factors and conclude – given all the data we have, is the phenomenon in question likely to be real or not, and with what magnitude?
So, for example, with ESP research, proponents often point to the low p-values and declare victory. This is nonsense, however. The results often have tiny effect sizes, are inconsistent from study to study, tend not to replicate (tend to decline to zero with repetition), and are starting with a very low prior probability (based on low overall scientific plausibility). Taken together, I think the most appropriate conclusion is that the results are most compatible with a world in which ESP does not exist as a real phenomenon. We certainly do not need to conclude that ESP is real in order to explain the results. Focusing entirely on the p-value, however, will not give you this perspective.
We also need to look at the overall patterns in the published literature. Is there publication bias, citation bias, evidence of p-hacking, how do exact replications fair, is there a consistent effect over time, etc.
To be fair, knowledgeable researchers, and the ones who tend to be recognized experts in legitimate fields, already know all this. If you read systematic reviews, this is what they talk about. The problem tends to exist more at the base level of researchers and also with the reporting of studies to the public.
I think the bottom line is that there is no utility to setting a cutoff for significance, and it has many unintended negative consequences (rampant p-hacking probably the most important). Journals and the academic culture should encourage and even require a more complete data analysis and interpretation. Let’s get away from the false dichotomy.
We also, then, need to come up with a vocabulary for communicating results to the press and the public. This should reflect the uncertainty inherent in research, and also force putting any single study into its proper scientific context (plausibility and other research). “Compatibility” is not a bad start, but needs to be combined with references to effect size, consistency, and plausibility.
If this makes the ultimate conclusion of scientific papers harder to bottom line – that is actually a good thing, I would argue. We actually don’t want journalists imposing their own bottom line based only on whether or not the results were statistically significant. Let them go to a researcher to put the results into context.




